
 Tiếng Việt
Tiếng ViệtSolutions, News, Stratus Technologies
What is High Availability (HA)? A Comprehensive Guide

In today’s interconnected world, downtime can be catastrophic for businesses. High availability (HA) is a critical system design approach that aims to minimize downtime and ensure continuous operation, even in the face of component failures. This comprehensive guide explores the core concepts of high availability, its benefits, challenges, and best practices.
What is High Availability?
High Availability refers to the design approach that minimizes the risk of downtime by eliminating single points of failure, ensuring long-lasting operations with limited interruptions. It involves redundant hardware and software components, along with failover mechanisms that automatically switch to backup components in case of failure. High Availability typically aims for specific uptime percentages, such as 99.99% (“four nines”) or 99.999% (“five nines”).
Key Components of High Availability Systems:
Several elements are vital to building a system with high availability:
- Redundancy: Duplicate components, such as servers, storage, and network paths, ensure that if one fails, another can take over.
- Load Balancing: Distributes workloads across multiple systems to prevent any single point of failure and maintain optimal performance.
- Failover Mechanisms: Automatically switch operations to a backup system or component when a primary system fails.
- Monitoring and Alerts: Continuous monitoring helps detect and respond to issues before they escalate into outages.
- Data Replication: Ensures data consistency across primary and backup systems, allowing seamless recovery.
- Clustered Systems: Groups of interconnected systems work together to ensure availability and share the workload.
How High Availability Works?
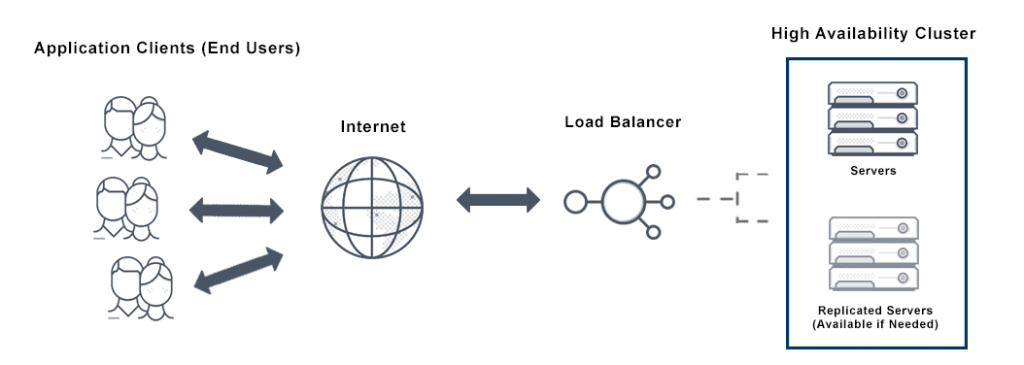
High Availability ensures continuous service delivery by implementing strategies that reduce downtime and quickly address failures. Here is a detailed explanation of how it works:
1. Redundancy in Components
High Availability systems are designed with multiple layers of redundancy. This includes duplicating hardware components like servers, storage devices, and power supplies, as well as software redundancies like backup databases and replicated applications. If one component fails, its redundant counterpart takes over seamlessly.
2. Failover Mechanisms
Failover is a critical process in HA systems. When a primary system detects a failure, it automatically transfers operations to a backup system or component. This transition is designed to be as smooth as possible, minimizing disruption to users. For example, in a server cluster, if one server goes offline, another server in the cluster will immediately handle the workload.
3. Load Balancing
Load balancers distribute incoming traffic or workloads across multiple servers or nodes in the system. By ensuring no single server is overwhelmed, load balancing not only enhances performance but also prevents potential system failures due to overloading.
4. Continuous Monitoring
Monitoring tools continuously check the health and performance of all system components. These tools provide real-time alerts about anomalies or failures, allowing IT teams to respond quickly. In many cases, automated responses can address issues without human intervention.
5. Data Replication
Data replication ensures that data is consistently mirrored across multiple locations or systems. This guarantees that in the event of a failure, the backup system has the most up-to-date data. Replication can be synchronous (real-time updates) or asynchronous (slightly delayed updates) depending on the system requirements.
6. Clustered Systems
In a High Availability cluster, multiple servers or nodes work together to provide a single service. The cluster’s architecture ensures that even if one or more nodes fail, the service remains operational by relying on the remaining active nodes. Heartbeat signals between nodes monitor their status, triggering failover mechanisms when necessary.
7. Automation and Orchestration
High Availability systems leverage automation tools to detect failures, initiate failovers, and restore services. Orchestration ensures that all components work harmoniously during both normal operations and recovery scenarios.
8. Regular Testing and Maintenance
HA systems are regularly tested to ensure failover mechanisms and redundancies are functioning correctly. Routine maintenance, including patch management and hardware checks, helps prevent failures and improves overall system reliability.
What Are High Availability Clusters?
High availability clusters are groups of interconnected servers that work together to provide continuous service. If one server in the cluster fails, the others take over its workload, ensuring uninterrupted operation. Clusters can be implemented using various technologies, including:
- Active-Active Clusters: All servers in the cluster are actively processing requests, distributing the workload for optimal performance.
- Active-Passive Clusters: One server is active, while the others are on standby. If the active server fails, a standby server takes over.
High Availability vs. Disaster Recovery:
While both high availability and disaster recovery aim to minimize downtime, they address different scenarios:
- High Availability: Focuses on preventing downtime due to component failures within a single data center or geographic location. It aims for near-continuous uptime.
- Disaster Recovery: Focuses on restoring operations after a major disaster that affects an entire data center or geographic region. It involves replicating data and systems to a secondary location.
High Availability vs. Fault Tolerance:
These terms are often used interchangeably, but there are key differences:
- High Availability: Aims to minimize downtime through redundancy and failover, allowing for short periods of interruption.
- Fault Tolerance: Aims for zero downtime by using specialized hardware and software that can continue operating even with multiple component failures. Fault-tolerant systems are typically more complex and expensive.
Benefits of High Availability:
High Availability (HA) refers to systems designed to ensure continuous operation and minimize downtime. Here are the key benefits of High Availability:
- Minimized Downtime: HA ensures that critical systems and services remain operational, reducing the impact of hardware or software failures and preventing costly outages.
- Improved Reliability: By employing redundancy and failover mechanisms, HA systems provide reliable and stable service, which is essential for mission-critical operations.
- Increased Productivity: With reduced downtime, employees can continue working without interruption, leading to improved overall productivity and efficiency.
- Better User Experience: HA ensures that customers or end-users experience fewer disruptions, leading to higher satisfaction and trust in your service.
- Business Continuity: HA systems help maintain service continuity even during emergencies or technical failures, ensuring the business remains operational under various conditions.
- Cost Efficiency: By preventing downtime, businesses avoid revenue losses and maintain consistent service delivery, reducing the long-term costs associated with outages.
- Scalability and Flexibility: HA systems are often designed to scale as your business grows, providing additional capacity and resources as needed without affecting service availability.
- Disaster Recovery: HA setups typically include disaster recovery mechanisms, ensuring that data is not lost and systems can be quickly restored in case of catastrophic failures.
Challenges of High Availability:
High Availability (HA) refers to systems, applications, or services that are designed to ensure continuous operation and minimize downtime, even in the event of failures. However, achieving high availability presents several challenges:
- Complex Design: HA requires complex architectures like load balancing and failovers, making it difficult to implement and maintain.
- High Cost: Implementing HA needs significant investment in redundant hardware, backup systems, and tools.
- Data Sync: Keeping data consistent across multiple servers can be tricky and error-prone.
- Scalability: Growing systems demand careful integration of additional resources without impacting performance.
- Recovery Time: Meeting strict recovery objectives during failovers or maintenance can be challenging.
- Maintenance: Continuous monitoring and regular updates are required to avoid issues.
- Disaster Recovery: A solid recovery plan is needed to handle large-scale failures.
- Human Error: Misconfigurations and errors can still lead to downtime.
- Network Issues: Network failures can affect HA systems even when hardware and software are fine.
- Testing: Validating HA mechanisms through extensive testing is time-consuming
How to Measure High Availability:
High Availability is quantified by measuring uptime and understanding how often systems experience downtime. Organizations use specific metrics to evaluate HA performance and ensure it meets business needs. Below are the primary metrics and methods to measure High Availability:
1. Uptime Percentage
The uptime percentage is the most widely used metric for High Availability. It represents the proportion of time a system is fully operational during a given period.
2. The “Nines” of Availability
High Availability is often described in terms of “nines,” reflecting different levels of reliability:
| Availability (%) | Downtime Per Year | Downtime Per Month | Downtime Per Week |
| 99% | ~3.65 days | ~7.2 hours | ~1.68 hours |
| 99.9% | ~8.76 hours | ~43.2 minutes | ~10.1 minutes |
| 99.99% | ~52.56 minutes | ~4.32 minutes | ~1.01 minutes |
| 99.999% | ~5.26 minutes | ~25.9 seconds | ~6.05 seconds |
3. Mean Time Between Failures (MTBF)
This measures the average operational time between system failures. A higher MTBF indicates greater reliability and fewer disruptions.
4. Mean Time to Recovery (MTTR)
This measures the average time it takes to restore a system to full functionality after a failure. A lower MTTR indicates faster recovery and higher availability.
5. Service Level Agreements (SLAs)
SLAs often define specific uptime targets and penalties for failing to meet them. Monitoring HA metrics helps organizations meet these contractual obligations and avoid financial or reputational harm.
6. Monitoring Tools and Dashboards
Modern systems rely on monitoring software to track uptime, downtime, and performance in real-time. These tools provide detailed logs and analytics to ensure compliance with HA objectives.
Examples of tools include:
- Nagios
- Zabbix
- New Relic
- SolarWinds
7. Incident Tracking and Analysis
To measure HA effectively, it’s crucial to document every downtime incident. Analyze the root cause, response time, and resolution process to identify trends and areas for improvement.
Best Practices for Implementing High Availability:
- Plan for Redundancy: Identify critical components and implement redundant systems to eliminate single points of failure.
- Automate Failover: Implement automated failover mechanisms to minimize manual intervention and ensure rapid recovery.
- Implement Robust Monitoring: Monitor system health and performance continuously to detect and address potential issues proactively.
- Regularly Test Failover: Conduct regular failover tests to ensure systems work as expected and identify areas for improvement.
- Document Procedures: Clearly document procedures for handling failures and restoring service to minimize downtime and ensure efficient recovery.
Use Case of High Availability:
- E-commerce Websites: Ensuring continuous online shopping experience for customers, maximizing sales and customer satisfaction.
- Financial Institutions: Maintaining uninterrupted access to banking services, ensuring customer trust and regulatory compliance.
- Healthcare Systems: Providing continuous access to patient records and critical medical systems, ensuring timely and effective patient care.
- Cloud Computing Platforms: Guaranteeing uptime for hosted applications and services, ensuring business continuity and customer satisfaction.
What does Stratus offer?
Stratus Technologies is the leading provider of infrastructure based solutions that keep your applications running continuously in today’s always-on world. Stratus Technologies’ always-on solutions can be rapidly deployed without changes to your applications. Our platform solutions provide end-to-end operational support with integrated hardware, software and services. Our software solutions are designed to provide always-on capabilities to applications running in your chosen environment – physical, virtualized or cloud. Our approach and our people enable us to identify problems that others miss and prevent application downtime before it occurs. Multiple layers of proactive diagnostic, monitoring and self-correcting services are backed by a global team of engineers who provide immediate support no matter where in the world your system is located.
Stratus offers a wide variety of edge computing solutions covering the full availability spectrum. From software only products like everRun, to complete solutions like ztC Edge and ftServer that include hardware, software, and services, Stratus helps customers easily and affordably deliver highly-available and fault-tolerant workloads.
If always-on is an application requirement, Stratus Technologies has a solution that fits.


