
 Tiếng Việt
Tiếng ViệtSolutions, News, Stratus Technologies
High Availability: Concept, Benefits, and Implementation Guide

In today’s connected, digital world, even brief periods of downtime can cause severe damage to a business’s revenue, reputation, and productivity. High Availability (HA) is a crucial system design approach aimed at minimizing downtime and ensuring continuous operation, even in the event of component failure.
This detailed article will provide all the information you need to know about High Availability: from its definition, operating principles, benefits, and common architectures, to implementation guidelines and comparisons with related concepts like Fault Tolerance and Disaster Recovery.
What is High Availability (HA)?
Definition of High Availability
High Availability (HA) refers to the ability of a system, service, or application to maintain operation and accessibility over a long period without interruption. The goal of HA is to completely eliminate or minimize the Single Point of Failure (SPOF).
A system is considered HA when it achieves a very high level of uptime, typically measured in “nines” of percentage, such as 99.99% (Four Nines) or 99.999% (Five Nines).
| Availability (%) | Annual Downtime | Monthly Downtime |
|---|---|---|
| 99% | ~3.65 days | ~7.2 hours |
| 99.9% (Three Nines) | ~8.76 hours | ~43.2 minutes |
| 99.99% (Four Nines) | ~52.56 minutes | ~4.32 minutes |
| 99.999% (Five Nines) | ~5.26 minutes | ~25.9 seconds |
How Does High Availability Work?
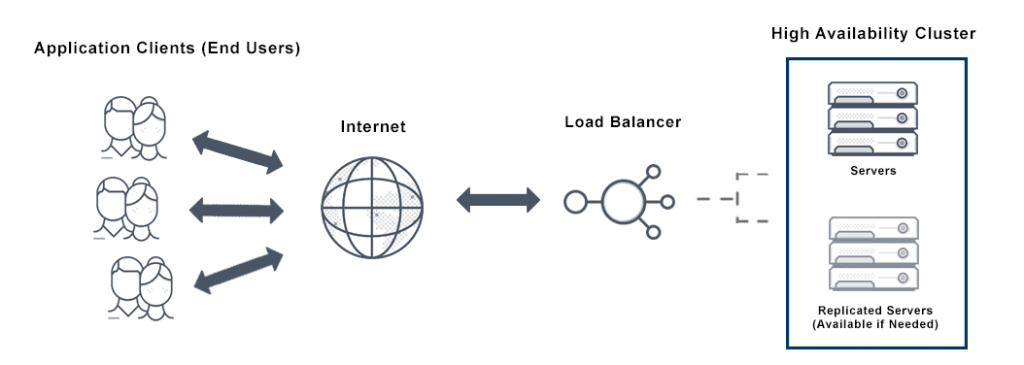
High Availability ensures continuous service operation by deploying automated prevention and incident response strategies:
- Component Redundancy: Deploying duplicate components (servers, network devices, storage, power supplies). If one component fails, a standby component takes over.
- Failover Mechanism: When the primary system detects a failure (via a Heartbeat signal), it automatically and quickly switches operations to the secondary/standby system.
- Load Balancing: Distributing the workload across multiple nodes, preventing overload and ensuring that a single node failure does not crash the entire service.
- Data Replication: Ensuring data is continuously synchronized (synchronous or asynchronous) between the primary and backup systems.
- Monitoring & Heartbeat: Monitoring tools constantly check the “live/dead” status of each node (via the heartbeat signal).
Practical Examples of High Availability
- Data Center: Using redundant power (UPS, generators), dual network paths, and N+1 cooling systems.
- E-commerce Website: Deploying multiple web servers running in parallel behind a Load Balancer. If one server fails, traffic is automatically rerouted to the remaining servers.
- Database System: Using a Database Cluster (e.g., PostgreSQL Replication or MySQL Group Replication) so that if the Master/Primary server fails, a Slave/Secondary server is automatically promoted (failover) to the new primary server.
Why is High Availability Crucial in Industrial & IT Systems?
Impact of Downtime on Business
Downtime is not just an inconvenience; it causes significant financial losses:
- Direct Revenue Loss: Online transactions and sales are halted.
- Productivity Decrease: Employees cannot access critical tools or systems to work.
- Contract Penalties (SLA): Violating commitments in the Service Level Agreement (SLA) with customers leads to compensation.
- Reputational Damage: Customers lose faith in the brand and switch to competitors.
- Regulatory Risk: Especially in finance and healthcare, downtime can lead to violations of data security regulations.
Stability Requirements in Industrial, OT/IT, and Data Center Systems
In industrial sectors, HA requirements are even higher:
- OT (Operational Technology): Production control, SCADA, and automation systems cannot be allowed to stop. One second of downtime can cause accidents or millions of dollars in material damage.
- Data Center: Must meet Tier III (99.982% uptime) or Tier IV (99.995% uptime) standards to ensure the continuous operation of all hosted services.
Relationship Between High Availability – Reliability – Resiliency – Fault Tolerance
| Concept | Focus | Objective |
|---|---|---|
| High Availability (HA) | Minimizing downtime via Redundancy & Failover. | Maintain near-100% continuous operation. |
| Reliability | The probability a system operates correctly under normal conditions. | Minimize the frequency of failure (high MTBF). |
| Fault Tolerance (FT) | Uninterrupted operation even when failures occur. | Zero downtime (often uses specialized hardware). |
| Resiliency | The ability to quickly recover after an incident or disaster. | Minimize recovery time (low MTTR). |
HA is a subset of Resiliency and an intermediary goal between Reliability and Fault Tolerance.
Benefits of High Availability
Implementing High Availability provides core competitive advantages for businesses:
Reduced Downtime
This is the biggest benefit. By establishing automatic failover mechanisms, HA ensures interruptions are measured in seconds or minutes, rather than hours.
Ensured Performance & Service Continuity
With Active-Active architecture and Load Balancing, HA not only prevents failure but also distributes the load, optimizing the application’s performance and responsiveness.
Enhanced User Experience
End-users (customers or employees) encounter fewer “Service Unavailable” errors, leading to higher satisfaction, trust, and loyalty to your service.
Data Protection and System Integrity
Data Replication is an essential part of HA, ensuring that data is not lost or corrupted, and the standby system always has the latest data.
Optimized Business Efficiency
Minimizing cost losses due to downtime and maintaining maximum labor productivity, thereby optimizing overall operational efficiency and profit.
Common High Availability Architectures
The choice of HA architecture depends on SLA, RTO/RPO requirements, and budget.
Active – Active
- Principle: All nodes (servers) are active and process requests simultaneously.
- Benefits: Maximizes performance, efficient load distribution, and offers better scalability.
- Drawbacks: Requires complex data synchronization mechanisms.
Active – Passive
- Principle: Only one node (Primary) is active, while the other (Secondary/Standby) is in a waiting state (hot/warm/cold standby).
- Benefits: Simpler data management.
- Drawbacks: The Passive node is unused, wasting resources. Failover may take longer than Active-Active.
Cluster High Availability
Uses cluster management software (Cluster Manager) to link multiple servers into a single system, managing Heartbeat and Failover.
Load Balancer + HA
Uses a Load Balancer to distribute the load while continuously monitoring the health of the servers. If a server fails, the Load Balancer automatically removes it from the distribution list.
Geo-redundancy
Deploying redundant systems in different geographical locations (e.g., two distant data centers) to protect against regional disasters.
HA combined with DR (Disaster Recovery)
Using HA within the same area (zone/DC) to handle local failures, and DR (in another region) to handle large-scale catastrophic failures.
Components and Design Principles for High Availability Systems
An effective HA system is built upon strict design principles:
Redundancy – Hardware & Software Duplication
Providing redundant components for every factor, including CPU, RAM, storage (RAID), power (N+1 capacity), and application/database software.
Failover – Automatic Switching on Failure
The mechanism for automatically switching from the primary system to the secondary system without human intervention. This is the core element for reducing MTTR.
Monitoring – Continuous Oversight
The monitoring system (like Nagios, Zabbix) must continuously check the performance, health status of each component, and critical metrics (CPU, Memory, Network I/O).
Heartbeat – Live/Dead Check Between Nodes
A network signal frequently sent between nodes in a cluster to determine if other nodes are active. If the Heartbeat signal is lost, the Failover mechanism is triggered.
Quorum – Voting Mechanism in a Cluster
In complex Cluster systems, Quorum is the voting mechanism that helps the remaining nodes decide which node has truly failed and needs to be isolated (Split-Brain Prevention).
Load Balancing – Traffic Distribution
Ensuring traffic is evenly distributed, preventing overload, and optimizing resource utilization.
Architecture Without Single Point of Failure (SPOF)
The golden rule of HA is to review and eliminate every SPOF—any component that, if it fails, will bring down the entire system.
High Availability in Cloud Computing
Major cloud providers (AWS, Azure, GCP) offer integrated tools to build cost-effective HA architectures.
High Availability in AWS
- AWS Multi-AZ: Deploying resources (like EC2, RDS) across multiple Availability Zones (AZs) within the same region. Each AZ is an independent data center.
- Elastic Load Balancer (ELB): Distributing traffic among EC2 instances in different AZs.
- Auto Scaling: Automatically adding or removing EC2 instances based on load demand, maintaining performance and resilience.
High Availability in Azure
- Availability Set: Grouping VMs to distribute them across different Fault Domains and Update Domains within a data center.
- Availability Zone: Deploying across physically separate locations within the same Region.
- Azure Load Balancer: Distributing traffic to VMs and other services.
High Availability in Google Cloud
- Compute Engine (GCE) Regional Architecture: Deploying VMs across multiple Zones within the same Region.
- Cloud SQL HA: Providing a Primary/Standby redundancy architecture with automatic failover between Zones.
- Load Balancing: Using Global External Load Balancing to distribute load across multiple Regions.
Comparing HA Across AWS – Azure – GCP
All three use the concept of Zone/AZ (Availability Zone) to provide protection against a single data center failure. The main difference lies in specialized services and naming conventions. However, the general principle remains Geo-redundancy and Load Balancing.
High Availability in Databases (Database HA)
The database is the most common SPOF. HA for databases requires perfect data replication.
SQL Server Always On High Availability
Provides a comprehensive HA and DR solution, including Always On Failover Cluster Instances (FCI) (HA) and Always On Availability Groups (AG) (HA and DR).
PostgreSQL High Availability (Replication, Failover, Cluster)
Uses Streaming Replication (synchronous or asynchronous replication) and cluster management tools like Patroni or repmanager to automate Failover.
MySQL / MariaDB High Availability
Uses Group Replication (multi-master configuration), Galera Cluster (synchronous multi-master), or traditional Master-Slave architecture with a Failover manager (like MHA).
MongoDB Replica Set & Sharding HA
- Replica Set: A group of MongoDB processes maintaining the same data set, providing redundancy and automatic Failover.
- Sharding: Distributing data across multiple servers for scalability, with each Shard also being a Replica Set to ensure HA.
Redis Sentinel & Redis Cluster HA
- Redis Sentinel: Provides monitoring, notification, and automatic Failover for Redis Master/Slave instances.
- Redis Cluster: Distributes data across multiple nodes (shards), each shard being a separate Master/Slave cluster.
Oracle High Availability (RAC, DataGuard)
- Real Application Clusters (RAC): Allows multiple Oracle instances to access the same database on shared storage (Active-Active).
- Data Guard: Provides redundancy and failover mechanisms (Primary/Standby) at the database or site level.
High Availability in Virtualization, Containers & Infrastructure
VMware vSphere High Availability
Monitors physical servers (ESXi) and virtual machines (VMs). If an ESXi host fails, vSphere HA automatically restarts those VMs on a healthy ESXi host.
Proxmox High Availability Cluster
The Proxmox VE (Virtual Environment) Cluster uses Corosync for communication and provides an automatic Failover mechanism for VMs and containers.
Kubernetes High Availability (Control Plane, Node, Pod)
- Control Plane HA: Ensuring there are at least 3 etcd and API Servers to maintain Cluster state even if a master node fails.
- Node HA: Deploying worker nodes across multiple AZs/DCs and using the Horizontal Pod Autoscaler (HPA) to ensure the number of Pods.
- Pod HA: Using ReplicaSet or Deployment to maintain a minimum number of Pod replicas.
High Availability in Network & Security Systems
Firewall High Availability (Palo Alto, FortiGate, pfSense, OPNSense)
Firewall devices are deployed in Active-Passive or Active-Active pairs to ensure continuous connectivity and uninterrupted security.
Router & Switch High Availability
Using protocols like VRRP (Virtual Router Redundancy Protocol) or HSRP (Hot Standby Router Protocol) to ensure a standby Router/Switch takes over the virtual IP of the primary device upon failure.
Load Balancer High Availability (Nginx, HAProxy)
The Load Balancer itself needs HA. It is often deployed in pairs (e.g., an HAProxy pair monitored by Keepalived) to prevent the Load Balancer from becoming an SPOF.
DNS High Availability
Using distributed DNS services across multiple geographical locations (like AWS Route 53, Cloudflare DNS) or deploying multiple redundant DNS servers.
Active Directory / IAM High Availability
Deploying multiple Domain Controllers (DCs) (with Active Directory) or using Cloud IAM services (like AWS IAM, Azure AD) which are designed with default HA.
High Availability in Storage & NAS
Synology High Availability (SHA)
Uses two Synology NAS devices (one Active, one Passive) to form a single storage server, providing Failover capability.
QNAP High Availability Cluster
Similar to SHA, linking two QNAP NAS devices to synchronize data and provide a failover mechanism.
Ceph Storage High Availability
Ceph is designed with HA by default through data replication across multiple storage nodes (OSDs) and using Monitors (MON) to maintain Quorum.
TrueNAS High Availability
Uses two TrueNAS devices (Active/Passive) with shared storage to provide Failover.
MinIO High Availability
MinIO, an S3-compatible object storage system, achieves HA by distributing data across multiple disks and servers (Erasure Coding), ensuring data is always available.
Steps to Implement High Availability for Businesses
To build a robust HA system, a structured deployment process must be followed:
Step 1 – Define Uptime Requirements (SLA 99.9% – 99.999%)
Determine the desired level of availability. A 99.999% requirement will be significantly more costly and complex than 99.9%. This decision dictates your architecture and budget.
Step 2 – Analyze Single Point of Failure (SPOF)
Conduct a comprehensive assessment to identify all components that could cause a complete system failure if they break down.
Step 3 – Select the Appropriate HA Architecture Model
Based on the uptime requirements (Step 1) and SPOF analysis (Step 2), choose the appropriate model (Active-Active, Active-Passive, Multi-AZ, etc.).
Step 4 – Establish Failover & Replication Mechanisms
Implement automatic Failover tools (e.g., Keepalived, Pacemaker) and data replication mechanisms (synchronous/asynchronous) between nodes.
Step 5 – Test HA Functionality (HA Test)
Conduct real-world tests by intentionally causing failures (e.g., pulling network cables, shutting down the primary node) to verify that the Failover mechanism works accurately and quickly.
Step 6 – Build Monitoring & Alert Mechanism
Set up a 24/7 monitoring system with real-time alerts so the IT team can react immediately to potential issues.
Step 7 – Operation, Maintenance & Periodic Review
HA is not a one-time setup. Regular maintenance, software/hardware updates, and periodic architectural reviews are needed to meet evolving business needs.
Challenges in Implementing High Availability
Despite its great benefits, HA implementation faces several hurdles:
High Investment & Operational Costs
The requirement for Redundancy means buying double (or more) hardware, software licenses, and cloud costs.
Architectural Complexity
Cluster systems, Data Replication, and automatic Failover are complex to design, configure, and fine-tune.
Risk of Misconfiguration
Configuration errors in the Failover mechanism or Data Replication can lead to Split-Brain (two nodes both thinking they are Primary) or data loss.
Dependence on Network Latency
In Geo-redundancy or synchronous Replication architectures, network latency between nodes can severely impact system performance.
Need for Highly Specialized Operations Team
The IT/DevOps team must have deep knowledge of Clustering, Failover, and monitoring tools to operate and maintain this complex system.
High Availability vs. Fault Tolerance vs. Disaster Recovery
| Feature | High Availability (HA) | Fault Tolerance (FT) | Disaster Recovery (DR) |
|---|---|---|---|
| Scope of Protection | Component failure, software failure, server failure. | Component failure, hardware failure. | Major disasters (floods, fires, DC power loss). |
| Downtime | Very low (seconds/minutes) | Zero (Zero Downtime) | Higher (minutes/hours/days) |
| Key Mechanism | Redundancy & Automatic Failover. | Specialized hardware, active replication (Active-Active-Active). | Data backup and restoration at a different site. |
| Cost | High | Very high (requires proprietary hardware) | Medium (depends on RTO/RPO) |
Similarities & Differences
- Similarities: All aim to ensure service continuity.
- Differences: HA accepts a very brief interruption, FT accepts no interruption, and DR focuses on recovery after a major disaster.
When to Use HA?
HA is a balance between cost and availability, suitable for most critical business applications and systems (requiring 99.9% to 99.999% uptime).
When is DR or FT Needed?
- FT: Only necessary for extremely critical applications, e.g., air traffic control systems, life support systems, stock trading (requiring zero downtime).
- DR: Always necessary, even with HA. DR protects the system from events beyond HA’s control (data center failure).
Stratus Solutions
Stratus Technologies is a leading provider of infrastructure solutions that keep your applications running continuously in today’s always-on world. Stratus’ always-on solutions can be deployed quickly without requiring changes to applications. Our platform solutions provide comprehensive operational support with integrated hardware, software, and services.
Our software solutions are designed to provide always-on capability for applications running in your environment – physical, virtualized, or cloud. Our approach and team help us identify issues others overlook and prevent application downtime before it occurs. Multiple layers of proactive diagnostic, monitoring, and self-healing services are backed by a global team of engineers, providing immediate support regardless of where your system is located in the world. Stratus offers a range of edge computing solutions covering the full spectrum of availability. From software like everRun, to integrated solutions like ztC Edge and ftServer that include hardware, software, and services, Stratus makes it easy and cost-effective for customers to deliver highly available and fault-tolerant workloads.
Servo Dynamics Engineering: Master Distributor of Penguin Solution (Formerly Stratus) in Vietnam
Given the rigorous challenges and requirements of High Availability in industrial (OT/IT) environments and Data Centers, selecting the right technology partner and solution is paramount.
Stratus Technologies is a leading provider of infrastructure solutions that help your applications operate always-on without requiring application changes. Stratus solutions, including software like everRun and integrated platforms like ztC Edge and ftServer (encompassing hardware, software, and services), help customers easily and cost-effectively achieve fault tolerance and high availability.
Servo Dynamics Engineering is proud to be the Master Distributor of Penguin Solution in Vietnam, delivering Stratus Technologies’ edge computing solutions and infrastructure platforms, helping Vietnamese businesses eliminate downtime and achieve the highest uptime goals.

