
 Tiếng Việt
Tiếng ViệtSolutions, Consulting, News
What is Availability? Applications & Operating Principles

Availability is one of the three core pillars of Information Security (IS) and a vital element for every technology system. In a digitized world where services must operate 24/7, ensuring High Availability (HA) is not only a technical goal but also a mandatory business requirement to maintain reputation and avoid financial losses.
This article will delve into explaining what Availability is, its constituent components, its important role in security, and the operating principles as well as methods for optimizing Availability for your system.
What is Availability?
Availability Concept in IT
In Information Technology (IT), Availability is a measure of the resilience and accessibility of a system, application, or service.
It is defined by the ratio of the time the system is actually running (or the service is successfully operating) divided by the total time the system is expected to operate. The basic formula is:
Availability = (Actual Operating Time (Uptime) / Total Expected Operating Time) x 100%
The result is usually expressed as a percentage (%).
Significance of Availability for Systems, Data, and Services
Availability holds key significance:
- Maintain Business Continuity: Ensures essential business processes, applications, and services are always accessible to end-users (customers or employees) without interruption.
- Protect Reputation: Every minute of service disruption (downtime) can diminish customer trust and severely affect brand reputation, especially in financial services, e-commerce, or healthcare sectors.
- Minimize Loss: Service interruption directly leads to loss of revenue, recovery costs, and potential penalties for violating Service Level Agreements (SLA).
What is Availability in English? (Availability – Definition)
In English, Tính Sẵn Sàng is Availability. This concept is often accompanied by other important terms like High Availability (HA) and Fault Tolerance.
Components of Availability
Achieving high availability requires a combination of several core components:
Accessibility (Availability)
This is the core aspect, focusing on ensuring the system is operating and accessible according to plan. It is the result of combining uptime and recovery time after a failure.
Usability
Usability relates to the ease with which users can utilize the system once accessed. A system might be “available” (running), but if the interface is faulty or responds too slowly to work effectively, it still doesn’t meet the “usable” standard.
System Scalability and High Availability
High Availability (HA) is a set of techniques and architectures established to ensure a certain level of availability, typically 99.9% or higher. Scalability is the ability to flexibly expand or contract resources (CPU, RAM, bandwidth) to meet changes in workload, thereby avoiding issues caused by overloading.
Resilience & Fault Tolerance
- Resilience: The system’s ability to quickly recover and return to normal operation after a failure or cyber attack.
- Fault Tolerance: The system’s ability to maintain continuous operation (without interruption) even when one or more internal components fail.
Role of Availability in Information Security (IS)
Availability in the CIA Triad Model
Availability is one of the three factors forming the basic information security model: the CIA Triad.
- Confidentiality: Ensures information is accessed only by authorized individuals.
- Integrity: Ensures information is not changed or destroyed without authorization.
- Availability: Ensures authorized users can access information and resources when needed.
If a system is absolutely secure but inaccessible (e.g., due to a DDoS attack), its availability has been violated.
What is Information Availability?
Information availability is the act of ensuring that data, data storage systems, and data transmission channels are always operational and allow users timely and unimpeded access.
Example of Availability in IS
A Distributed Denial of Service (DDoS) attack is a classic example of an availability violation. The attacker floods the network or server resources with fake traffic, overwhelming the system and preventing it from serving legitimate requests from real users.
Comparison: Confidentiality – Integrity – Availability
| Aspect | Primary Goal | Example of Technical Measure |
|---|---|---|
| Confidentiality | Preventing unauthorized access | Data encryption, Access Control Lists (ACL), Multi-Factor Authentication (MFA) |
| Integrity | Preventing unauthorized modification | Digital signatures, Hashing, Version control |
| Availability | Ensuring continuous access | Redundancy mechanism, Backup, Load Balancing |
System and Data Availability

What is System Availability?
This is the ability of a computer system, server, or application to operate without failure for an extended period. It is a statistical measure often calculated by the number of “nines” as follows:
Systems are often classified by their level of availability based on the number of “nines”. Depending on your interruption costs, even 1% downtime (equivalent to 4 days/year) can result in significant losses.
| Availability | Number of “Nines” | Maximum Downtime Per Year | Commonly Described as |
|---|---|---|---|
| 99.9% | Three Nines | Less than 526 minutes (8.76 hours) | Available |
| 99.99% | Four Nines | Less than 53 minutes | High Availability |
| 99.999% | Five Nines | Less than 5 minutes | Fault Tolerant |
Systems with availability of “four nines” or higher are often referred to as High Availability (HA) or Fault Tolerant systems.
Data and Application Availability
Availability applies not only to hardware but also to data and applications. Data must always be accessible, consistent, and uncorrupted. Applications need to be designed for fast recovery, such as using database clusters or Microservices architecture so that a failure in a small service doesn’t crash the entire application.
Product Availability in Industry & IoT
In industrial environments (like manufacturing plants, smart grids) and the Internet of Things (IoT), availability is extremely crucial. The failure of a sensor, PLC (Programmable Logic Controller), or SCADA server can lead to production shutdown, equipment damage, or even safety hazards. These systems require high resilience, often Fault Tolerance, to ensure uninterrupted operation.
Principles of Availability Operation
High availability is built upon several core technical principles:
Distributed Principle
Instead of concentrating all resources at a single point (single point of failure), a distributed architecture splits the workload and data across multiple servers or geographical locations. If one server or region fails, other components can still take over.
Redundancy – Mechanism for Increasing Availability
Redundancy is the most basic principle. It involves duplicating (or multiplying) critical system components, such as power sources (UPS, generators), hard drives (RAID), or entire servers. When the primary component fails, the redundant component automatically switches to operation.
Replication – Data Cloning
Replication is the real-time or near-real-time copying of data between different servers or data centers. This ensures that if the primary server fails, the latest data is still available on the backup servers.
Failover – Switching When the System Fails
Failover is the automated process of redirecting service requests from a failed component to a functioning redundant component. This is an automatic mechanism, helping to reduce downtime to nearly zero.
Load Balancing – Keeps the System Running
Load Balancing distributes incoming traffic across multiple servers. This not only optimizes performance by preventing a single server from being overloaded but also increases availability: if a server in the group stops responding, the load balancer automatically removes it and only sends traffic to the remaining operational servers.
High Availability (HA)
What is High Availability?
High Availability (HA) is a standard for system design and operation aimed at eliminating Single Points of Failure (SPoF) and ensuring continuous service operation. HA typically requires three nines (99.9%) or higher.
How to Evaluate Availability Index (Uptime %)
The availability index is evaluated by the ratio of operating time (Uptime). For example:
| Availability | Uptime (%) | Maximum Downtime/Year | Maximum Downtime/Week |
|---|---|---|---|
| 99.9% | 99.9% | 8 hours 45 minutes | 10 minutes 05 seconds |
| 99.99% | 99.99% | 52 minutes 36 seconds | 1 minute 01 second |
| 99.999% | 99.999% | 5 minutes 15 seconds | 6 seconds |
High Availability Deployment Models
HA is usually deployed under major cluster models:
- Active – Active: Both (or more) servers in the cluster handle traffic and service requests simultaneously. When one server fails, the remaining server(s) take over the entire load. Advantage: Optimized performance and resource utilization.
- Active – Standby: Only one server (Active) is running and processing requests. The other server (Standby) is in waiting mode, synchronizing data and ready to take over immediately when the Active server fails (Failover). Advantage: Simpler and easier to manage state.
- HA Cluster: A group of computers working together as a single system. HA Cluster solutions (e.g., Kubernetes, VMware HA) monitor status and automatically restart applications or switch virtual machines upon detecting failure.
Pros & Cons of HA
| Aspect | Pros | Cons |
|---|---|---|
| Pros | Minimizes downtime, protects revenue and reputation, meets strict SLA requirements, increases overall performance. | Higher initial investment costs due to required redundant resources (double or more), more complex architecture and operation, requires high specialized expertise for management. |
Availability Requirements in Networking & IPv6
IPv6 Availability Requirements
In IPv6 networks, availability relates not only to servers but also to continuous network access capability. Due to address expansion and greater connectivity needs, IPv6 network mechanisms must ensure scalability and redundancy at the address and routing level.
Network Mechanisms to Increase Availability
Network protocols providing availability:
- RA (Router Advertisement): Allows IPv6 devices to automatically discover and configure default gateways, ensuring fast network connection.
- SLAAC (Stateless Address Autoconfiguration): Allows devices to automatically assign IP addresses without a DHCP server, reducing single points of failure.
- DHCPv6 (Dynamic Host Configuration Protocol for IPv6): Provides centralized network configuration, but also requires redundant deployment (e.g., DHCPv6 Hot Standby servers).
Ensuring Availability When Scaling Out the System
When scaling out (Scale Out) the system, the following principles should be applied to ensure availability:
- Geo-Redundancy: Deploy Data Centers in multiple geographical regions to protect against natural disasters or widespread outages.
- Smart Routing (Anycast/BGP): Uses advanced routing protocols to automatically redirect traffic to the nearest or currently operational data center.
Real-world Applications of Availability
Data Center
Modern Data Centers must comply with TIER levels (I-IV) for availability. TIER IV requires absolute redundancy (Fault Tolerance) with N+N power, cooling, and network systems.
Server – Cloud – Virtualization Systems
- Cloud Computing: Cloud service providers (AWS, Azure, GCP) build HA into their architecture through Availability Zones and Managed Services with automatic Failover.
- Virtualization: Platforms like VMware and Hyper-V provide HA features, automatically migrating or restarting Virtual Machines (VMs) on other physical servers when the current server fails.
Industrial & Automation Systems
In Operational Technology (OT) environments, the availability of control systems like SCADA, DCS, and PLC is extremely important to ensure uninterrupted production lines and operational safety.
Applications in Smart Manufacturing, SCADA & MES
SCADA (Supervisory Control and Data Acquisition) and MES (Manufacturing Execution System) systems require nearly 100% fault tolerance. Hardware or software failures can lead to material damage. Therefore, fault-tolerant Edge Computing solutions like Stratus ftServer or ztC Edge are often used to ensure five nines (99.999%) availability.
How to Improve System Availability
Design Redundant Architecture
Start by designing an architecture without Single Points of Failure. Apply redundancy at every level: Network (two connections), hardware (dual power supply, RAID), and servers (Failover Cluster).
Regular Maintenance & System Monitoring
Regularly update software, firmware, and check system health to prevent failures. Deploy Monitoring Tools to identify and alert early on potential issues (e.g., high temperature, resource depletion).
Use Load Balancer & Clustering
Deploy Load Balancers to distribute load and use Clustering technologies (server clusters) to automate the failover process, reducing RTO (Recovery Time Objective).
Backup – Restore Policy
Establish a comprehensive backup strategy:
- Regular Backup: Ensure data is backed up frequently (hourly/daily).
- Recovery Testing: Most importantly, regularly test the recovery (Restore) process to ensure data can be retrieved and the system can resume operation within the established RTO timeframe.
Implement Security to Prevent Service Interruption
Security is a part of availability. Apply measures like firewalls, intrusion detection/prevention systems (IDS/IPS), and anti-DDoS to protect the system from attacks that could interrupt service.
Data Backup and Recovery Implementation
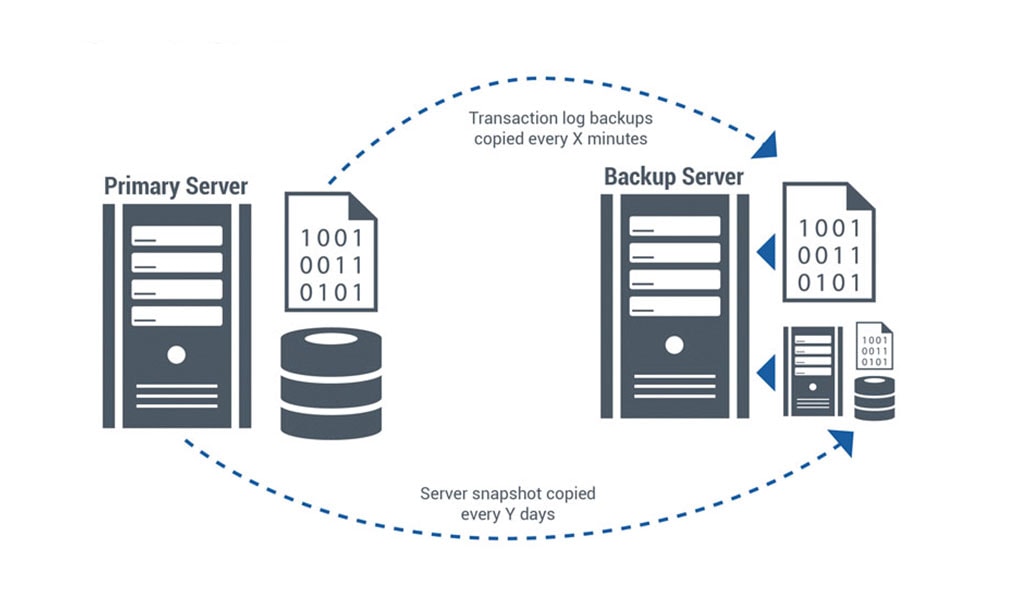
No matter how reliable a system is, limitations still exist. In many cases, not only system availability but also data protection and ensuring data integrity are very important. Businesses with a comprehensive availability strategy often perform regular data backups and maintain a standby system. If the production system experiences a serious failure, they can quickly restore service on the standby system and retrieve data from the archive. Setting up backup and recovery systems requires expertise and skill. Recovery time can range from a few hours to several days, depending on the application, data volume, and availability of replacement components.
Use of Clustering and Natural and Virtual Failover Services
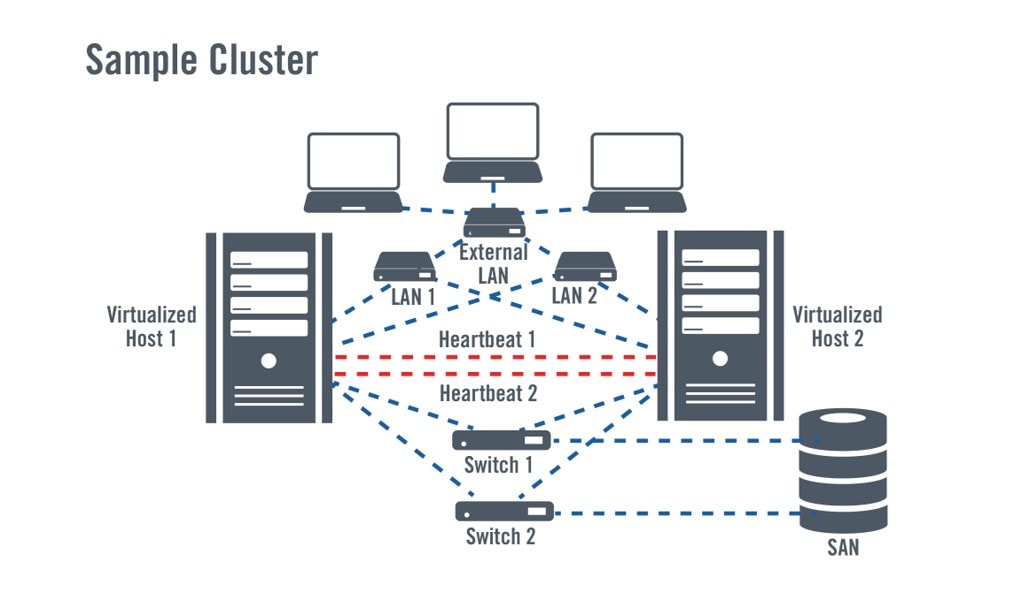
For some businesses, restoring service after a few hours or days may be acceptable. But for businesses with high interruption costs, they need a stronger solution to ensure applications and data are always ready. Clustering and failover work based on similar principles as backup and recovery, but shorten recovery time by performing some preparatory steps, such as duplicating the system so it can operate immediately when needed. Multiple systems are combined and share data with each other.
Typically, a primary system will be responsible for providing applications and data to users, while a secondary system acts as a standby, which can be in a passive state or running other applications (active). When the primary system fails, the application will “failover” to the secondary system and continue operating, as long as the connection to the data is maintained. With the development of virtualization technology, the concepts of clustering and failover have been extended to virtual systems. Today, virtualization and clustering technology are used to combine physical systems, while also supporting failover for applications running on Virtual Machines (VMs), leveraging VM mobility.
What Penguine Solution (Formerly Stratus) Offers?
Stratus technology provides many edge computing solutions suitable for different availability requirements. From software products like everRun, to complete solutions like ztC Edge and ftServer, including hardware, software, and services. Stratus helps customers easily deploy highly available and robust fault-tolerant systems effectively and cost-efficiently.
Servo Dynamics Engineering: Master Distributor of Penguine Solution in Vietnam
To achieve high availability and absolute fault tolerance, solutions from Stratus Technologies (such as everRun, ztC Edge, and ftServer) are the top choice. In Vietnam, Servo Dynamics Engineering is the Master Distributor of Penguine Solution, providing Stratus’s leading fault-tolerant edge computing solutions, helping businesses easily deploy five nines systems effectively and cost-efficiently.


