
 English
EnglishGiải pháp, Stratus Technologies Việt Nam, Tin tức
Tính Sẵn Sàng Cao (High Availability): Khái Niệm, Lợi Ích & Cách Triển Khai

Trong thế giới kỹ thuật số và kết nối ngày nay, thời gian ngừng hoạt động (downtime) dù ngắn ngủi cũng có thể gây thiệt hại nghiêm trọng về doanh thu, uy tín và năng suất cho doanh nghiệp. Tính Sẵn Sàng Cao (High Availability – HA) là một phương pháp thiết kế hệ thống tối quan trọng, nhằm giảm thiểu thời gian ngừng hoạt động và đảm bảo hoạt động liên tục, ngay cả khi gặp sự cố về thành phần.
Bài viết chi tiết này sẽ cung cấp mọi thông tin bạn cần biết về High Availability: từ định nghĩa, nguyên lý hoạt động, lợi ích, các kiến trúc phổ biến, đến hướng dẫn triển khai và so sánh với các khái niệm liên quan như Fault Tolerance và Disaster Recovery.
Tính Sẵn Sàng Cao (High Availability) là gì?
Định nghĩa High Availability
High Availability (HA) đề cập đến khả năng của một hệ thống, dịch vụ hoặc ứng dụng để duy trì hoạt động và truy cập trong một khoảng thời gian dài mà không bị gián đoạn. Mục tiêu của HA là loại bỏ hoàn toàn hoặc giảm thiểu tối đa Điểm Lỗi Duy Nhất (Single Point of Failure – SPOF).
Một hệ thống được coi là có HA khi nó đạt được mức độ uptime (thời gian hoạt động) rất cao, thường được đo bằng “số 9” (nines) trong phần trăm, ví dụ: 99,99% (Four Nines) hoặc 99,999% (Five Nines).
| Availability (%) | Thời gian Downtime mỗi năm | Downtime mỗi tháng |
|---|---|---|
| 99% | ~3.65 ngày | ~7.2 giờ |
| 99.9% (Three Nines) | ~8.76 giờ | ~43.2 phút |
| 99.99% (Four Nines) | ~52.56 phút | ~4.32 phút |
| 99.999% (Five Nines) | ~5.26 phút | ~25.9 giây |
High Availability hoạt động như thế nào?
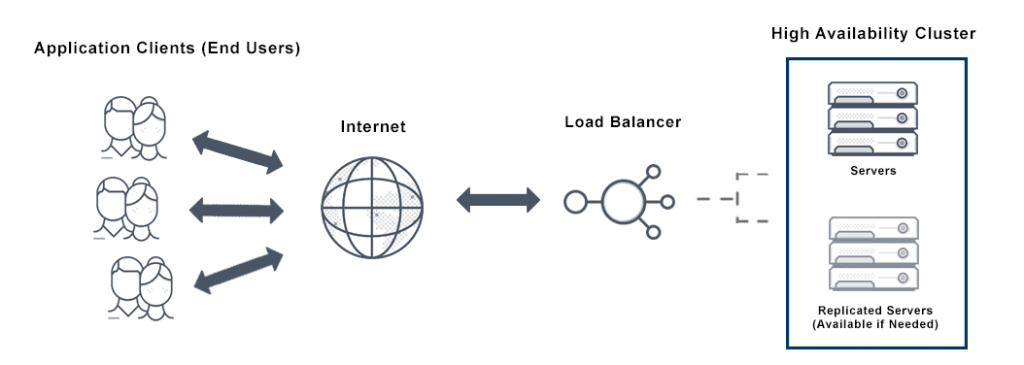
High Availability đảm bảo dịch vụ luôn hoạt động liên tục bằng cách triển khai các chiến lược phòng ngừa và xử lý sự cố tự động:
- Dự phòng linh kiện (Redundancy): Triển khai các thành phần trùng lặp (máy chủ, thiết bị mạng, bộ lưu trữ, nguồn điện). Nếu một thành phần bị lỗi, một thành phần dự phòng sẽ tiếp quản.
- Cơ chế chuyển đổi (Failover): Khi hệ thống chính phát hiện sự cố (thông qua Heartbeat), nó tự động và nhanh chóng chuyển đổi hoạt động sang hệ thống dự phòng.
- Cân bằng tải (Load Balancing): Phân phối khối lượng công việc trên nhiều node, ngăn ngừa quá tải và đảm bảo rằng sự cố của một node không làm sập toàn bộ dịch vụ.
- Sao chép dữ liệu (Data Replication): Đảm bảo dữ liệu được đồng bộ hóa liên tục (synchronous hoặc asynchronous) giữa hệ thống chính và hệ thống sao lưu.
- Giám sát (Monitoring) & Heartbeat: Các công cụ giám sát liên tục kiểm tra tình trạng “sống/chết” của từng node (thông qua tín hiệu heartbeat).
Ví dụ thực tế về High Availability
- Data Center: Sử dụng nguồn điện dự phòng (UPS, máy phát điện), đường truyền mạng kép, và hệ thống làm mát N+1.
- Website Thương mại điện tử: Triển khai nhiều máy chủ web chạy song song sau một Load Balancer. Nếu một máy chủ bị lỗi, lưu lượng truy cập sẽ tự động được chuyển hướng sang các máy chủ còn lại.
- Hệ thống Database: Sử dụng Database Cluster (ví dụ: PostgreSQL Replication hoặc MySQL Group Replication) để khi máy chủ chính (Master/Primary) sập, một máy chủ dự phòng (Slave/Secondary) sẽ tự động được thăng cấp (failover) thành máy chủ chính mới.
Vì sao High Availability quan trọng trong hệ thống công nghiệp & CNTT?
Ảnh hưởng của downtime đến doanh nghiệp
Thời gian ngừng hoạt động (downtime) không chỉ là sự bất tiện; nó gây ra tổn thất tài chính đáng kể:
- Thiệt hại doanh thu trực tiếp: Các giao dịch, bán hàng trực tuyến bị dừng lại.
- Giảm năng suất: Nhân viên không thể truy cập các công cụ hoặc hệ thống quan trọng để làm việc.
- Phạt hợp đồng (SLA): Vi phạm cam kết trong Thỏa thuận Mức dịch vụ (Service Level Agreement – SLA) với khách hàng, dẫn đến bồi thường.
- Tổn thất uy tín: Khách hàng mất niềm tin vào thương hiệu và chuyển sang đối thủ cạnh tranh.
- Rủi ro pháp lý: Đặc biệt trong các ngành tài chính, y tế, downtime có thể dẫn đến vi phạm quy định về bảo mật dữ liệu.
Các yêu cầu về độ ổn định trong hệ thống công nghiệp, OT/IT, Data Center
Trong các ngành công nghiệp, yêu cầu HA còn cao hơn:
- OT (Operational Technology): Các hệ thống điều khiển sản xuất, SCADA, và tự động hóa không được phép dừng. Một giây downtime có thể gây ra tai nạn hoặc thiệt hại vật chất hàng triệu đô la.
- Data Center: Cần đạt chuẩn Tier III (99.982% uptime) hoặc Tier IV (99.995% uptime) để đảm bảo tính liên tục của tất cả các dịch vụ lưu trữ.
Mối liên hệ giữa High Availability – Reliability – Resiliency – Fault Tolerance
| Khái niệm | Tập trung vào | Mục tiêu |
|---|---|---|
| High Availability (HA) | Giảm thiểu downtime thông qua Redundancy & Failover. | Duy trì hoạt động liên tục (gần như 100%). |
| Reliability (Độ tin cậy) | Xác suất hệ thống hoạt động chính xác trong điều kiện bình thường. | Giảm thiểu tần suất xảy ra lỗi (MTBF cao). |
| Fault Tolerance (Khả năng chịu lỗi) | Hoạt động không gián đoạn ngay cả khi lỗi xảy ra. | Downtime bằng 0 (thường dùng phần cứng chuyên dụng). |
| Resiliency (Khả năng phục hồi) | Khả năng phục hồi nhanh chóng sau một sự cố hoặc thảm họa. | Giảm thiểu thời gian khôi phục (MTTR thấp). |
HA là một tập hợp con của Resiliency và là mục tiêu trung gian giữa Reliability và Fault Tolerance.
Lợi ích của High Availability
Triển khai High Availability mang lại nhiều lợi thế cạnh tranh cốt lõi cho doanh nghiệp:
Giảm thời gian dừng (downtime)
Đây là lợi ích lớn nhất. Bằng cách thiết lập cơ chế tự động chuyển đổi, HA đảm bảo thời gian gián đoạn chỉ còn tính bằng giây hoặc phút, thay vì hàng giờ.
Đảm bảo hiệu suất & tính liên tục của dịch vụ
Với kiến trúc Active-Active và Load Balancing, HA không chỉ giúp ngăn lỗi mà còn phân phối tải, tối ưu hóa hiệu suất và khả năng phản hồi của ứng dụng.
Nâng cao trải nghiệm người dùng
Người dùng cuối (khách hàng hoặc nhân viên) sẽ ít gặp lỗi “Service Unavailable” hơn, dẫn đến sự hài lòng, tin cậy và lòng trung thành cao hơn với dịch vụ.
Bảo vệ dữ liệu và tính toàn vẹn của hệ thống
Data Replication là một phần thiết yếu của HA, đảm bảo rằng dữ liệu không bị mất hoặc hỏng, và hệ thống dự phòng luôn có dữ liệu mới nhất.
Tối ưu hoá hiệu quả kinh doanh
Giảm thiểu tổn thất chi phí do downtime và duy trì năng suất lao động ở mức cao nhất, từ đó tối ưu hóa hiệu quả hoạt động và lợi nhuận tổng thể.
Các kiến trúc High Availability phổ biến
Việc lựa chọn kiến trúc HA phụ thuộc vào yêu cầu về SLA, RTO/RPO và ngân sách.
Active – Active
- Nguyên lý: Tất cả các node (máy chủ) đều hoạt động và xử lý yêu cầu đồng thời.
- Lợi ích: Tối đa hóa hiệu suất, phân phối tải hiệu quả, và cung cấp khả năng mở rộng (scalability) tốt hơn.
- Nhược điểm: Yêu cầu cơ chế đồng bộ hóa dữ liệu phức tạp.
Active – Passive
- Nguyên lý: Chỉ có một node (Primary) hoạt động, node còn lại (Secondary/Standby) ở trạng thái chờ (hot/warm/cold standby).
- Lợi ích: Đơn giản hơn về mặt quản lý dữ liệu.
- Nhược điểm: Node Passive không được sử dụng, lãng phí tài nguyên. Quá trình Failover có thể mất nhiều thời gian hơn Active-Active.
Cluster High Availability
Sử dụng phần mềm quản lý cụm (Cluster Manager) để liên kết nhiều máy chủ thành một hệ thống duy nhất, quản lý Heartbeat và Failover.
Load Balancer + HA
Sử dụng bộ cân bằng tải (Load Balancer) để phân phối tải và đồng thời theo dõi tình trạng của các máy chủ. Nếu một máy chủ thất bại, Load Balancer tự động loại máy chủ đó khỏi danh sách phân phối.
Geo-redundancy
Triển khai các hệ thống dự phòng tại các vị trí địa lý khác nhau (ví dụ: hai trung tâm dữ liệu cách xa nhau) để bảo vệ chống lại thảm họa khu vực.
HA kết hợp DR (Disaster Recovery)
Sử dụng HA trong cùng một khu vực (zone/DC) để xử lý lỗi cục bộ, và DR (tại khu vực khác) để xử lý lỗi thảm họa quy mô lớn.
Thành phần và nguyên tắc thiết kế hệ thống High Availability
Một hệ thống HA hiệu quả được xây dựng dựa trên các nguyên tắc thiết kế nghiêm ngặt:
Redundancy – Dư thừa phần cứng & phần mềm
Cung cấp các thành phần dự phòng cho mọi yếu tố, bao gồm CPU, RAM, ổ cứng (RAID), nguồn điện (công suất N+1), và phần mềm ứng dụng/database.
Failover – Tự động chuyển đổi khi lỗi
Cơ chế tự động chuyển đổi từ hệ thống chính sang hệ thống dự phòng mà không cần sự can thiệp của con người. Đây là yếu tố cốt lõi để giảm MTTR.
Monitoring – Giám sát liên tục
Hệ thống giám sát (như Nagios, Zabbix) phải liên tục kiểm tra hiệu suất, tình trạng sức khỏe của từng thành phần, và các chỉ số quan trọng (CPU, Memory, Network I/O).
Heartbeat – Kiểm tra sống/chết giữa các node
Là tín hiệu mạng được gửi thường xuyên giữa các node trong cluster để xác định xem các node khác có đang hoạt động hay không. Nếu tín hiệu Heartbeat bị mất, cơ chế Failover sẽ được kích hoạt.
Quorum – Cơ chế biểu quyết trong cluster
Trong các hệ thống Cluster phức tạp, Quorum là cơ chế bỏ phiếu giúp các node còn lại quyết định xem node nào đã thực sự thất bại và cần bị cô lập (Split-Brain Prevention).
Load balancing – Phân phối tải
Đảm bảo lưu lượng truy cập được phân bổ đều, ngăn chặn quá tải, và tối ưu hóa việc sử dụng tài nguyên.
Kiến trúc không có single point of failure (SPOF)
Nguyên tắc vàng của HA là rà soát và loại bỏ mọi SPOF—bất kỳ thành phần nào, nếu bị lỗi, sẽ làm sập toàn bộ hệ thống.
High Availability trong Cloud Computing
Các nhà cung cấp dịch vụ đám mây lớn (AWS, Azure, GCP) cung cấp các công cụ tích hợp để xây dựng kiến trúc HA với chi phí hiệu quả.
High Availability trong AWS
- AWS Multi-AZ: Triển khai tài nguyên (như EC2, RDS) trên nhiều Availability Zones (AZ) trong cùng một khu vực. Mỗi AZ là một trung tâm dữ liệu độc lập.
- Elastic Load Balancer (ELB): Phân phối lưu lượng truy cập giữa các phiên bản EC2 ở các AZ khác nhau.
- Auto Scaling: Tự động thêm hoặc bớt phiên bản EC2 dựa trên nhu cầu tải, duy trì hiệu suất và khả năng phục hồi.
High Availability trong Azure
- Availability Set: Nhóm các VM lại với nhau để phân tán chúng trên các miền lỗi (Fault Domains) và miền cập nhật (Update Domains) trong một trung tâm dữ liệu.
- Availability Zone: Triển khai trên các khu vực vật lý tách biệt trong cùng một Region.
- Azure Load Balancer: Phân phối lưu lượng truy cập đến các VM và dịch vụ khác.
High Availability trong Google Cloud
- Compute Engine (GCE) Regional Architecture: Triển khai các VM trên nhiều Zone trong cùng một Region.
- Cloud SQL HA: Cung cấp kiến trúc dự phòng (Primary/Standby) tự động chuyển đổi giữa các Zone.
- Load Balancing: Sử dụng Global External Load Balancing để phân phối tải trên nhiều Region.
So sánh HA giữa AWS – Azure – GCP
Cả ba đều sử dụng khái niệm Zone/AZ (Vùng sẵn sàng) để cung cấp khả năng bảo vệ chống lại lỗi trung tâm dữ liệu đơn lẻ. Sự khác biệt chủ yếu nằm ở các dịch vụ chuyên biệt và cách đặt tên. Tuy nhiên, nguyên lý chung vẫn là Dự phòng địa lý cục bộ (Geo-redundancy) và Cân bằng tải.
High Availability trong Cơ sở dữ liệu (Database HA)
Database là SPOF phổ biến nhất. HA cho cơ sở dữ liệu đòi hỏi việc sao chép dữ liệu hoàn hảo.
SQL Server Always On High Availability
Cung cấp giải pháp HA và DR toàn diện, bao gồm Always On Failover Cluster Instances (FCI) (HA) và Always On Availability Groups (AG) (HA và DR).
PostgreSQL High Availability (replication, failover, cluster)
Sử dụng Streaming Replication (sao chép đồng bộ hoặc không đồng bộ) và các công cụ quản lý cụm như Patroni hoặc repmanager để tự động hóa Failover.
MySQL / MariaDB High Availability
Sử dụng Group Replication (dạng multi-master), Galera Cluster (multi-master đồng bộ), hoặc kiến trúc Master-Slave truyền thống với công cụ quản lý Failover (như MHA).
MongoDB Replica Set & Sharding HA
- Replica Set: Một nhóm các quy trình MongoDB duy trì cùng một bộ dữ liệu, cung cấp dự phòng và tự động Failover.
- Sharding: Phân tán dữ liệu trên nhiều máy chủ để mở rộng quy mô, đồng thời các Shard cũng là Replica Set để đảm bảo HA.
Redis Sentinel & Redis Cluster HA
- Redis Sentinel: Cung cấp giám sát, thông báo và tự động Failover cho các instance Redis Master/Slave.
- Redis Cluster: Phân tán dữ liệu trên nhiều node (shards), mỗi shard là một cụm Master/Slave riêng biệt.
Oracle High Availability (RAC, DataGuard)
- Real Application Clusters (RAC): Cho phép nhiều instance Oracle truy cập cùng một cơ sở dữ liệu trên bộ lưu trữ dùng chung (Active-Active).
- Data Guard: Cung cấp cơ chế dự phòng và chuyển đổi dự phòng (Primary/Standby) ở cấp độ cơ sở dữ liệu hoặc trang web.
High Availability trong Ảo hoá, Container & Hạ tầng
VMware vSphere High Availability
Giám sát các máy chủ vật lý (ESXi) và các máy ảo (VMs). Nếu một máy chủ ESXi gặp sự cố, vSphere HA sẽ tự động khởi động lại các VMs đó trên một máy chủ ESXi khỏe mạnh khác.
Proxmox High Availability Cluster
Proxmox VE (Virtual Environment) Cluster sử dụng Corosync để liên lạc và cung cấp cơ chế Failover tự động cho các máy ảo và container.
Kubernetes High Availability (Control Plane, Node, Pod)
- Control Plane HA: Đảm bảo có ít nhất 3 etcd và API Servers để duy trì trạng thái Cluster ngay cả khi một node master bị lỗi.
- Node HA: Triển khai các worker node trên nhiều AZ/DC và sử dụng Horizontal Pod Autoscaler (HPA) để đảm bảo số lượng Pods.
- Pod HA: Sử dụng ReplicaSet hoặc Deployment để duy trì số lượng bản sao Pod tối thiểu.
High Availability trong Hệ thống mạng & bảo mật
Firewall High Availability (Palo Alto, FortiGate, pfSense, OPNSense)
Các thiết bị Tường Lửa (Firewall) được triển khai theo cặp Active-Passive hoặc Active-Active để đảm bảo kết nối liên tục và bảo mật không gián đoạn.
Router & Switch High Availability
Sử dụng các giao thức như VRRP (Virtual Router Redundancy Protocol) hoặc HSRP (Hot Standby Router Protocol) để đảm bảo một Router/Switch dự phòng sẽ tiếp quản IP ảo của thiết bị chính khi có lỗi.
Load Balancer High Availability (Nginx, HAProxy)
Bản thân Load Balancer cũng cần HA. Thường được triển khai theo cặp (ví dụ: một cặp HAProxy được giám sát bởi Keepalived) để tránh Load Balancer trở thành SPOF.
DNS High Availability
Sử dụng dịch vụ DNS phân tán trên nhiều vị trí địa lý (như AWS Route 53, Cloudflare DNS) hoặc triển khai nhiều máy chủ DNS dự phòng.
Active Directory / IAM High Availability
Triển khai nhiều Domain Controllers (DC) (với Active Directory) hoặc sử dụng các dịch vụ IAM của Cloud (như AWS IAM, Azure AD) được thiết kế với HA mặc định.
High Availability trong lưu trữ & NAS
Synology High Availability (SHA)
Sử dụng hai thiết bị NAS Synology (một Active, một Passive) để tạo thành một máy chủ lưu trữ duy nhất, cung cấp tính năng Failover.
QNAP High Availability Cluster
Tương tự như SHA, liên kết hai NAS QNAP với nhau để đồng bộ hóa dữ liệu và cung cấp cơ chế chuyển đổi dự phòng.
Ceph Storage High Availability
Ceph được thiết kế với HA mặc định thông qua việc nhân bản dữ liệu trên nhiều node lưu trữ (OSDs) và sử dụng Monitors (MON) để duy trì Quorum.
TrueNAS High Availability
Sử dụng hai thiết bị TrueNAS (Active/Passive) với bộ lưu trữ dùng chung để cung cấp Failover.
MinIO High Availability
MinIO, một hệ thống lưu trữ đối tượng (object storage) tương thích S3, đạt HA bằng cách phân tán dữ liệu trên nhiều ổ đĩa và máy chủ (Erasure Coding), đảm bảo dữ liệu luôn có sẵn.
Các bước triển khai High Availability cho doanh nghiệp
Để xây dựng một hệ thống HA vững chắc, cần tuân thủ một quy trình triển khai có cấu trúc:
Bước 1 – Xác định yêu cầu uptime (SLA 99.9% – 99.999%)
Xác định mức độ sẵn sàng mong muốn. Yêu cầu 99.999% sẽ tốn kém và phức tạp hơn rất nhiều so với 99.9%. Việc này quyết định kiến trúc và ngân sách của bạn.
Bước 2 – Phân tích single point of failure (SPOF)
Thực hiện đánh giá toàn diện để xác định tất cả các thành phần có thể gây ra lỗi toàn bộ hệ thống nếu chúng bị hỏng.
Bước 3 – Chọn mô hình kiến trúc HA phù hợp
Dựa trên yêu cầu uptime (Bước 1) và kết quả SPOF (Bước 2), chọn mô hình thích hợp (Active-Active, Active-Passive, Multi-AZ, v.v.).
Bước 4 – Thiết lập cơ chế failover & replication
Triển khai các công cụ tự động Failover (ví dụ: Keepalived, Pacemaker) và cơ chế sao chép dữ liệu (đồng bộ/không đồng bộ) giữa các node.
Bước 5 – Kiểm thử tính năng HA (HA Test)
Thực hiện các bài kiểm tra thực tế bằng cách cố tình gây ra lỗi (ví dụ: rút cáp mạng, tắt nguồn node chính) để xác minh cơ chế Failover hoạt động chính xác và nhanh chóng.
Bước 6 – Xây dựng cơ chế monitoring & alert
Thiết lập hệ thống giám sát 24/7 với các cảnh báo theo thời gian thực (real-time alerts) để đội ngũ IT có thể phản ứng ngay lập tức với các vấn đề tiềm ẩn.
Bước 7 – Vận hành, bảo trì & đánh giá định kỳ
HA không phải là thiết lập một lần. Cần bảo trì định kỳ, cập nhật phần mềm/phần cứng, và đánh giá lại kiến trúc thường xuyên để đáp ứng nhu cầu kinh doanh đang thay đổi.
Những thách thức khi triển khai High Availability
Mặc dù mang lại lợi ích lớn, việc triển khai HA cũng đối mặt với nhiều rào cản:
Chi phí đầu tư & vận hành
Yêu cầu về Redundancy (dư thừa) có nghĩa là phải mua gấp đôi (hoặc nhiều hơn) phần cứng, giấy phép phần mềm, và chi phí đám mây.
Độ phức tạp kiến trúc
Các hệ thống Cluster, Data Replication, và Failover tự động rất phức tạp để thiết kế, cấu hình và tinh chỉnh.
Rủi ro cấu hình sai
Lỗi cấu hình trong cơ chế Failover hoặc Data Replication có thể dẫn đến Split-Brain (hai node cùng nghĩ mình là Primary) hoặc mất dữ liệu.
Phụ thuộc vào network latency
Trong kiến trúc Geo-redundancy hoặc Replication đồng bộ, độ trễ mạng (network latency) giữa các node có thể ảnh hưởng nghiêm trọng đến hiệu suất hệ thống.
Cần đội ngũ vận hành có chuyên môn cao
Đội ngũ IT/DevOps phải có kiến thức sâu rộng về Clustering, Failover và các công cụ giám sát để vận hành và bảo trì hệ thống phức tạp này.
High Availability vs Fault Tolerance vs Disaster Recovery
| Tính năng | High Availability (HA) | Fault Tolerance (FT) | Disaster Recovery (DR) |
|---|---|---|---|
| Phạm vi bảo vệ | Lỗi thành phần, lỗi phần mềm, lỗi máy chủ. | Lỗi thành phần, lỗi phần cứng. | Thảm họa lớn (lũ lụt, cháy nổ, mất điện DC). |
| Thời gian ngừng hoạt động | Rất thấp (giây/phút) | Bằng không (Zero Downtime) | Cao hơn (phút/giờ/ngày) |
| Cơ chế chính | Redundancy & Failover tự động. | Phần cứng chuyên dụng, nhân bản hoạt động (Active-Active-Active). | Sao lưu dữ liệu và khôi phục tại địa điểm khác. |
| Chi phí | Cao | Rất cao (yêu cầu phần cứng độc quyền) | Trung bình (phụ thuộc vào RTO/RPO) |
Giống nhau & khác nhau
- Giống nhau: Cùng nhằm mục đích đảm bảo tính liên tục của dịch vụ.
- Khác nhau: HA chấp nhận một khoảng gián đoạn rất ngắn, FT không chấp nhận gián đoạn, còn DR tập trung vào việc khôi phục sau một thảm họa lớn.
Khi nào dùng HA?
HA là giải pháp cân bằng giữa chi phí và tính sẵn sàng, phù hợp với hầu hết các ứng dụng và hệ thống kinh doanh quan trọng (yêu cầu 99.9% đến 99.999% uptime).
Khi nào cần DR hoặc FT?
- FT: Chỉ cần thiết cho các ứng dụng có tính chất cực kỳ quan trọng, ví dụ: hệ thống điều khiển giao thông hàng không, hệ thống hỗ trợ sự sống, giao dịch chứng khoán (yêu cầu downtime bằng 0).
- DR: Luôn cần thiết, ngay cả khi đã có HA. DR bảo vệ hệ thống khỏi các sự kiện ngoài tầm kiểm soát của HA (lỗi trung tâm dữ liệu).
Giải pháp của Stratus?
Stratus Technologies là nhà cung cấp hàng đầu các giải pháp hạ tầng giúp các ứng dụng của bạn hoạt động liên tục trong thế giới luôn hoạt động ngày nay. Các giải pháp luôn hoạt động của Stratus có thể được triển khai nhanh chóng mà không cần thay đổi ứng dụng. Các giải pháp nền tảng của chúng tôi cung cấp hỗ trợ vận hành toàn diện với phần cứng, phần mềm và dịch vụ tích hợp.
Các giải pháp phần mềm của chúng tôi được thiết kế để cung cấp khả năng luôn hoạt động cho các ứng dụng chạy trong môi trường của bạn – vật lý, ảo hóa hoặc đám mây. Phương pháp tiếp cận và đội ngũ của chúng tôi giúp chúng tôi nhận diện các vấn đề mà người khác bỏ qua và ngăn chặn thời gian chết của ứng dụng trước khi nó xảy ra. Nhiều lớp dịch vụ chẩn đoán chủ động, giám sát và tự sửa chữa được hỗ trợ bởi đội ngũ kỹ sư toàn cầu, cung cấp hỗ trợ ngay lập tức bất kể hệ thống của bạn ở đâu trên thế giới.
Stratus cung cấp nhiều giải pháp điện toán biên bao phủ toàn bộ phạm vi tính khả dụng. Từ các phần mềm như everRun, đến các giải pháp như ztC Edge và ftServer bao gồm phần cứng, phần mềm và dịch vụ, Stratus giúp khách hàng dễ dàng và tiết kiệm chi phí trong việc cung cấp các khối lượng công việc có tính sẵn sàng cao và chống lỗi.
Servo Dynamics Engineering: Nhà phân phối Master của Penguin Solution (Trước đây là Stratus) tại Việt Nam
Với những thách thức và yêu cầu khắt khe của High Availability trong môi trường công nghiệp (OT/IT) và Data Center, việc lựa chọn đối tác và giải pháp công nghệ là vô cùng quan trọng.
Stratus Technologies là nhà cung cấp hàng đầu các giải pháp hạ tầng giúp các ứng dụng của bạn hoạt động luôn luôn sẵn sàng (always-on) mà không cần thay đổi ứng dụng hiện có. Các giải pháp của Stratus, bao gồm phần mềm như everRun và các nền tảng tích hợp như ztC Edge và ftServer (bao gồm cả phần cứng, phần mềm và dịch vụ), giúp khách hàng dễ dàng và tiết kiệm chi phí trong việc đạt được khả năng chịu lỗi và tính sẵn sàng cao.
Servo Dynamics Engineering tự hào là Nhà phân phối Master của Penguin Solution tại Việt Nam, mang đến các giải pháp điện toán biên và nền tảng hạ tầng của Stratus Technologies, giúp doanh nghiệp Việt Nam loại bỏ downtime và đạt được mục tiêu uptime cao nhất.

